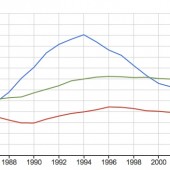
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of BIBFRAME, it was the season of RDA, it was the spring of hope, it […]